Построение масок теней от облаков на данных ДЗЗ с помощью ГИС GRASS
Как сделать маску теней
Статья продолжает серию публикаций, посвященную использованию ГИС GRASS для мониторинга природных процессов. Ранее на эту тему были опубликованы статьи Анализ данных с использованием ГИС GRASS и R и Нейросетевая обработка данных в ГИС GRASS и R
Обсудить в форуме Комментариев — 7
Оглавление
1. Описание задачи
Облака и тени от облаков затрудняют анализ поверхности Земли по данным ДЗЗ, поскольку они искажают спектральные характеристики поверхности. Поэтому предварительно созданые маски облаков и их теней могут в дальнейшем облегчить решение основной задачи, стоящей перед исследователем.
В данной статье дается пример использования связки геоинформационной системы GRASS и аналитического пакета R для построения масок облаков и их теней. В виду того, что построения маски теней - более сложная задача, чем построение маски облачности, в данной статье основной упор будет сделан на задачу поиска теней.
В качестве примера рассмотрим конкретный снимок A2000.109, для которого будет строится маска, представленый ниже (композитное изображение ближнего инфракрасного и красного каналов, данные MODIS):
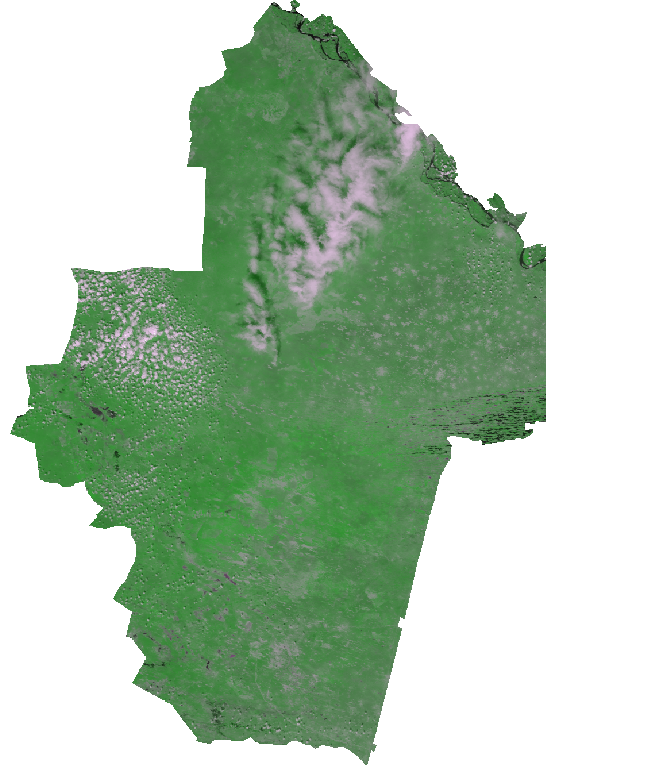 Исходное композитное RGB изображение, синтез 1-2-1, данные MODIS. Видна облачность разного типа в северной части снимка. Щелкните на изображении для увеличения.
Исходное композитное RGB изображение, синтез 1-2-1, данные MODIS. Видна облачность разного типа в северной части снимка. Щелкните на изображении для увеличения.
2. Реализация
Как видно, на снимке довольно много мелких облаков и, соответственно, теней, поэтому строить маску вручную - долго и утомительно. Выделять тени автоматически, на основе их спектральных характеристик также довольно хлопотно, т.к. эти характеристики меняются в зависимости от того, на какую поверхность упала тень. Поэтому для ускорения работы воспользуемся ранее описанным методом поиска изменений. Для этого выберем близкий по времени снимок с меньшим числом облаков (A2000.105):
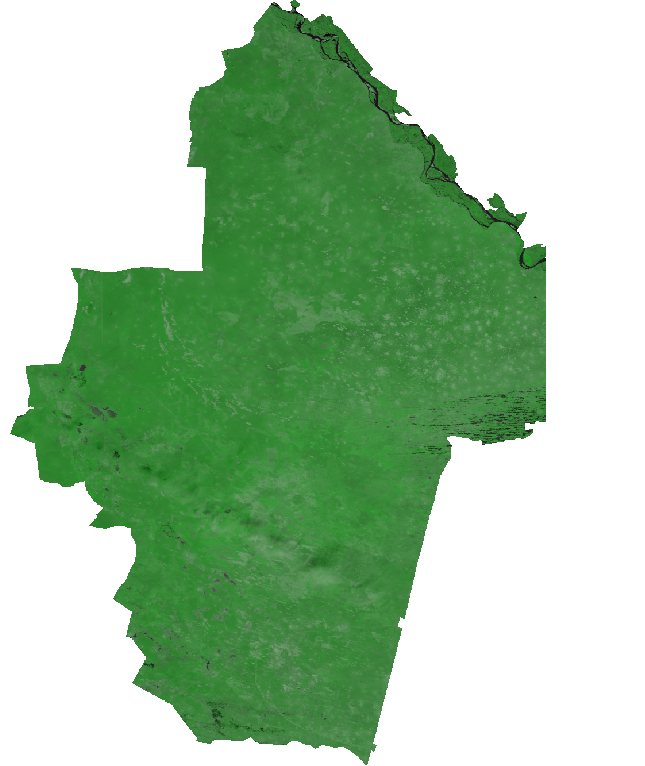 Второе исходное композитное RGB изображение, синтез 1-2-1, 3 апреля 2000, данные MODIS. Щелкните на изображении для увеличения.
Второе исходное композитное RGB изображение, синтез 1-2-1, 3 апреля 2000, данные MODIS. Щелкните на изображении для увеличения.
Далее была построена нейронная сеть, которая была обучена по данным второго изображения (A2000.105) возвращать значения первого (A2000.109). В результате были получены две разности (для каждого канала в отдельности) между реальным и ожидаемым значением dif1 и dif2:
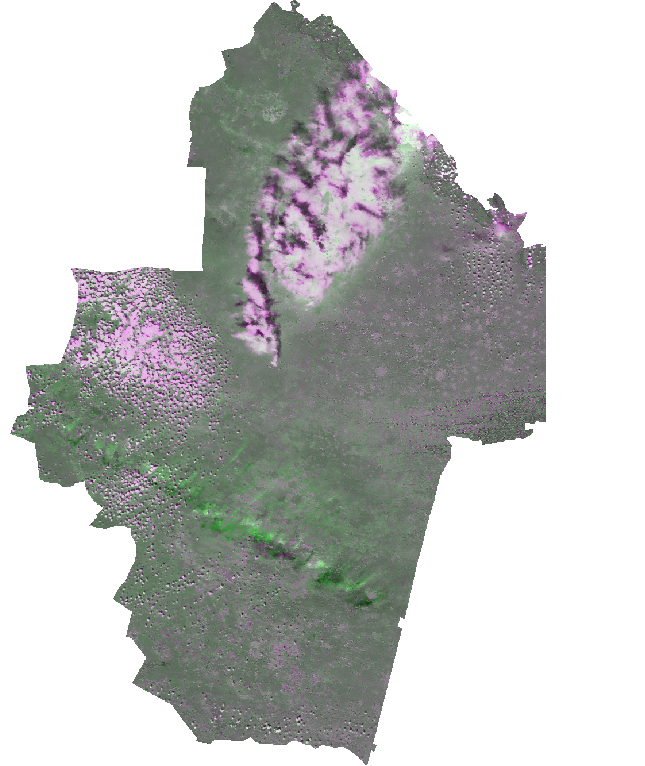 Производное изобрежение. Щелкните на изображении для увеличения.
Производное изобрежение. Щелкните на изображении для увеличения.
На этом изображении на сером фоне хорошо просматриваются облака и их тени. Далее нужно подобрать какой-либо разумный порог, по которому можно отделить тень от фона. Однако, при внимательном рассмотрении становится понятно, что такого порога не существует.
Дело в том, что облако на полученном изображении выглядит как "белое пятно", а тень - как "черное пятно". Черные пятна получаются там, где ожидаемые значения выше, чем полученные из нейронной сети. Для рассматриваемых снимков по большей части справедливо то, что, если в реальности на каком-либо участке снимка яркость меньше, чем предсказано сетью, то это произошло потому, что на данный участок упала тень. Но есть исключение: темное пятно появится и в случае, если на входном снимке было облако - тогда значение, предсказанное сетью также больше, чем в реальности.
На фрагменте композитного изображения, составленного из разностей, видна полоса, темная часть которой соответствует участку снимка A2000.105, закрытого облаком:
 Фрагмент производного изображения с ошибочной областью. Щелкните на изображении для увеличения.
Фрагмент производного изображения с ошибочной областью. Щелкните на изображении для увеличения.
Таким образом, какой порог бы мы не подбирали для при анализе разностей dif1 и dif2, в получившуюся маску будут попадать также и участки, закрытые облаками на снимке A2000.105. Чтобы отсечь этот случай, при выделении теней потребуется анализировать не два растра (dif1 и dif2), а как минимум три (dif1, dif2 и A2000.105.1 - первый канал снимка A2000.105).
Для автоматизации построения маски теней произведем совместную классификацию трех изображений dif1, dif2 и A2000.105.1. на основе классификации без обучения.
В ГИС GRASS классификация производится в два этапа:
- Генерируются спектральные сигнатуры на основе алгоритма кластеризации. Существует несколько модулей, генерирующих сигнатуры, мы воспользуемся i.cluster.
- На основе полученных сигнатур производится собственно классификация, будем использовать метод максимального правдоподобия i.maxlik.
Классификация
В ГИС GRASS перед классификацией изображений необходимо сначала создать группу, в которую войдут изображения, предназначенные для анализа.
# Сгруппируем растры для анализа: i.group group=teni subgroup=day2000.109 in=dif1,dif.2,norm_A2000.109.1
Модуль i.cluster принимает несколько параметров, влияющих на качество классификации. В первую очередь, это начальное количество кластеров (classes), степень устойчивости получаемых кластеров (convergence) и порог, согласно которому кластеры могут быть объеденены в один (separation). Создадим файл сигнатур teni5, начальное число кластеров положим равным пяти, остальные параметры оставим по умолчанию:
i.cluster group=teni subgr=day2000.109 sigfile=teni5 class=5
В результате был получен следующий файл сигнатур:
#produced by i.cluster #Class 1 373 -0.12203 -0.241684 0.376518 0.00844029 0.00233836 0.0136008 -0.00448385 -0.00433758 0.0196701 #Class 2 1918 -0.00415582 0.0130466 0.33635 0.00683429 0.00219023 0.00673684 0.000368992 -0.00033016 0.00399067 #Class 3 1564 0.0116323 0.0108282 0.543228 0.0078622 0.00168063 0.00564052 -0.000900678 -0.000136028 0.00490507 #Class 4 880 0.048829 0.0377407 0.820891 0.015089 0.00750132 0.0125422 0.000641942 -0.000832052 0.00859291 #Class 5 643 0.525218 0.370767 0.396278 0.0129791 0.00806127 0.0236968 -0.00599599 0.000977332 0.0138644
Каждый выделенный класс описан средними значениями и матрицей ковариаций (на примере первого класса):
373 # число примеров обучающего множества, отнесенных к данному классу -0.12203 -0.241684 0.376518 # средние значения пикселей класса для растров dif1,dif2 и norm_A2000.109.1 соответственно # матрица ковариаций: 0.00844029 0.00233836 0.0136008 -0.00448385 -0.00433758 0.0196701
Далее производим собственно классификацию, для этого передадим модулю полученный файл сигнатур:
i.maxlik group=teni subgr=day2000.109 sigfile=teni5 clas=cluster5_2000.109 --o
Результат (фрагмент центрального участка) можно посмотреть на следующем рисунке:
 Результат классификации, фрагмент . Щелкните на изображении для увеличения.
Результат классификации, фрагмент . Щелкните на изображении для увеличения.
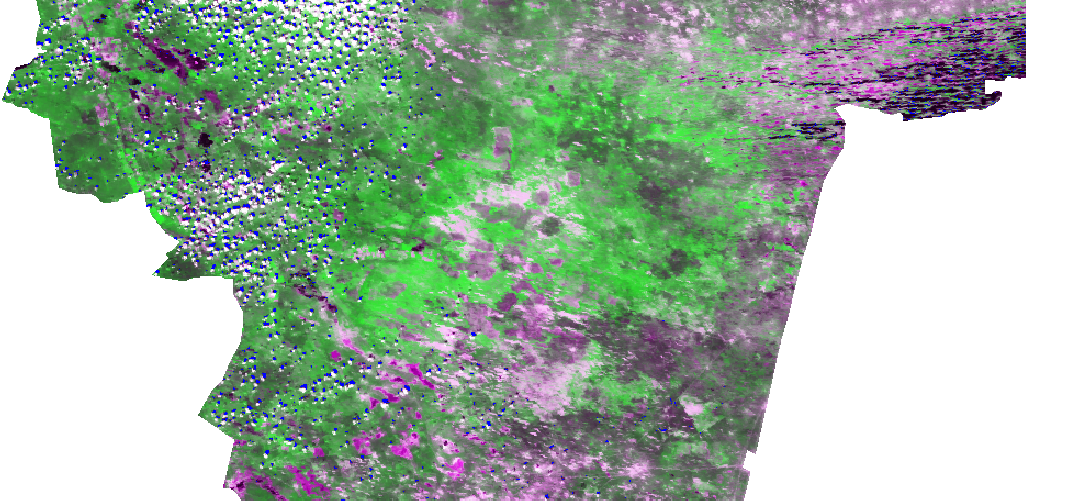
Для большей наглядности можно установить прозрачность для всех классов, кроме 1-го и подложить снимок:
 Результат классификации, класс теней наложенный на снимок. Щелкните на изображении для увеличения.
Результат классификации, класс теней наложенный на снимок. Щелкните на изображении для увеличения.
и
 Результат классификации, класс теней наложенный на снимок, нижняя часть, ошибки на востоке. Щелкните на изображении для увеличения.
Результат классификации, класс теней наложенный на снимок, нижняя часть, ошибки на востоке. Щелкните на изображении для увеличения.
Чисто визуально - большая часть теней распознана правильно, темная полоса, которая ошибочно воспринималась как тень на растрах dif1 и dif2, не была выделена в класс теней, однако, в восточной части участка есть области, которые явно ошибочно отнесены к разряду теней. Если внимательно посмотреть на исходные снимки, то становится понятным, то эти области - водные объекты - множество мелких озер-ильменей. Поэтому для более корректной классификации можно попробовать два пути:
- Изменить параметры кластеризации (по идее вода должна хорошо отделяться).
- Добавить к анализируемым изображениям растр, хранящий маску воды.
Первый путь проще, с него и начнем:
i.cluster group=teni subgr=day2000.109 sigfile=teni20 class=20 con=99.5 i.maxlik group=teni subgr=day2000.109 sigfile=teni20 clas=cluster20_2000.109 --o
Результат показан ниже:
 Окончательная классификация, класс теней наложенный на снимок. Щелкните на изображении для увеличения.
Окончательная классификация, класс теней наложенный на снимок. Щелкните на изображении для увеличения.
Как видим, в результате были отсечены ложные срабатывания на участках, покрытых водой - теперь они не относятся к классу теней.
Обсудить в форуме Комментариев — 7
Ссылки по теме
Последнее обновление: September 09 2021
Дата создания: 09.01.2011
Автор(ы): Дмитрий Колесов, Максим Дубинин



© GIS-Lab и авторы, 2002-2021. При использовании материалов сайта, ссылка на GIS-Lab и авторов обязательна. Содержание материалов - ответственность авторов. (подробнее).