Поскольку не знаю общепринятых ключевых слов постараюсь поподробнее описать суть проблемы.
Часто полевые данные собираются не случайным образом, а так, что где-то пусто, а где-то густо. И эта картина отражает не столько специфику распространения самого объекта, сколько специфику самого сбора данных. Например, в ООПТ точек встреч редких видов обычно существенно больше, чем вне ООПТ. Это совсем не означает, что в ООПТ действительно концентрация редких видов выше, особенно в таком малоосвоенном регионе как таежная зона Западной Сибири. А означает, что там живут научные сотрудники которые регулярно экскурсируют по территории.
Так вот получается, что перед построением модели, точки нужно как-то "нормализовать" в пространстве, чтобы их частота в пространстве была примерно одинаковой как в ООПТ, так и вне их. При этом хочется потерять как можно меньше данных (выкинуть как можно меньше точек).
Напрашивается кластеризация точек с каким-то радиусом. В таком случае возникает вопрос, как этот радиус найти?
P.S. Про пространственную аутокорреляцию я в курсе, это не совсем про нее, похоже. Хотя возможно как-то использовать методы учета пространственной аутокорреляци и в данном случае.
"Нормализация" точечных данных в пространстве
-
bolotoved
- Гуру
- Сообщения: 920
- Зарегистрирован: 30 дек 2008, 14:11
- Репутация: 236
- Откуда: Ханты-Мансийск
- Контактная информация:
-
jerry-maori

- Гуру
- Сообщения: 585
- Зарегистрирован: 22 авг 2012, 17:02
- Репутация: 143
- Откуда: Нижний Новгород
Re: "Нормализация" точечных данных в пространстве
В Махеnt такое называется sampling bias. там решают путём добавления слоя, где каждому пикселю присваивают вес как раз для учёта эффекта "рядом с научным сотрудником скотинка бегает чаще"
http://onlinelibrary.wiley.com/doi/10.1 ... 6/abstract
http://onlinelibrary.wiley.com/doi/10.1 ... 6/abstract
-
bolotoved
- Гуру
- Сообщения: 920
- Зарегистрирован: 30 дек 2008, 14:11
- Репутация: 236
- Откуда: Ханты-Мансийск
- Контактная информация:
Re: "Нормализация" точечных данных в пространстве
Видимо, в более общем случае это называется declustering: spatial declustering или cell declustering. Тут вот приводится метода расчета искомого размера ячейки: http://geostatisticslessons.com/lessons ... clustering
По ходу дела напоролся на раздел учебника по ArcGIS по геостатистике, там тоже эта тема затронута, хотя и без ссылок, зато есть на русском.
По ходу дела напоролся на раздел учебника по ArcGIS по геостатистике, там тоже эта тема затронута, хотя и без ссылок, зато есть на русском.
-
Максим Дубинин

- MindingMyOwnBusiness
- Сообщения: 9129
- Зарегистрирован: 06 окт 2003, 20:20
- Репутация: 748
- Ваше звание: NextGIS
- Откуда: Москва
- Контактная информация:
Re: "Нормализация" точечных данных в пространстве
А по мне так совсем про неё. И тогда выбирать шаг/разрешение можно примерно так:bolotoved писал(а):P.S. Про пространственную аутокорреляцию я в курсе, это не совсем про нее, похоже.
Код: Выделить всё
'import data
d = read.csv(file = "c:/temp/test.csv", header = T)
attach(d)
geodata = data.frame(cbind(X, Y, Presabs, resid))
'If X,Y are coordinates, then it possible to check if data imported correctly, geographic pattern should look the same with the map
'If Presabs contains 0 for absence and 1 for presence, this will make a thematic map of locations with absence and presence data colored differently
'cex parameter will make graduated symbols
plot(X,Y)
plot(X,Y, col=Presabs+1)
plot(X,Y, col=Presabs+1, cex=abs(resid))
'Load and install a package
library(geoR)
'Convert data to geodata format, coords - coordinates, data - values
geodata1 = as.geodata(geodata, coords.col = 1:2, data.col = 4)
'Make a variogram
'Remove tails
variogram = variog(geodata1)
variogram = variog(geodata1, max.dist = 0.066)
plot(variogram)
'Create Monte-Carlo Envelope for variogram using iteratively permutated (shuffled) residuals
envelope = variog.mc.env(geodata1, obj.variog = variogram)
'Show calculated envelope with the variogram, if data points all fall into envelope it means that data is not spatially autocorrelated
plot.variogram(variogram, envelope.obj = envelope)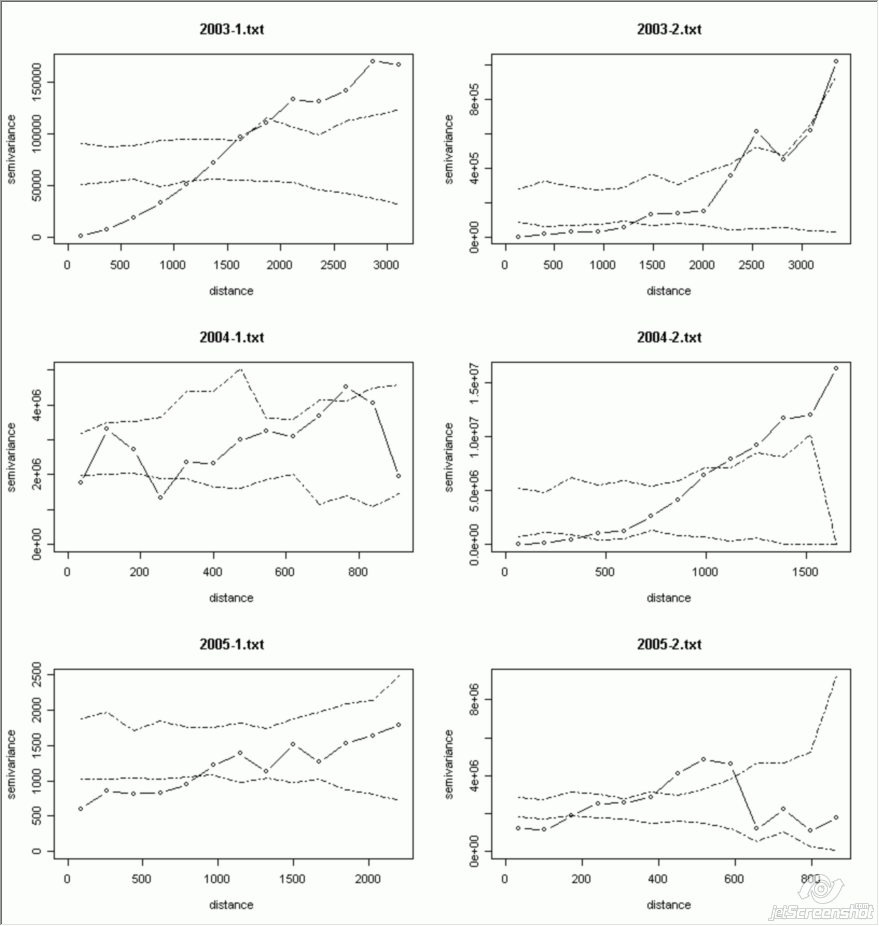
пристегивайтесь, турбулентность прямо по курсу
-
gamm
- Гуру
- Сообщения: 4168
- Зарегистрирован: 15 окт 2010, 08:33
- Репутация: 1107
- Ваше звание: программист
- Откуда: Казань
Re: "Нормализация" точечных данных в пространстве
строго говоря, речь идет о нарушении независимости "независимых" переменных, которая обычно предполагается при моделировании (есть еще термин pseudoreplication, про это же). Проблема возникает, если выборка становится смещенной, например, преобладает один тип ландшафта, места с высокой влажностью, исследуемое явление имеет "пятнистую" пространственную структуру, и т.д.
Учесть ее можно, например оценив sampling efforts (которые могут выражены в обследованной площади или времени, потраченном на обследование), в R для этого есть offset (т.е. переходим к относительным величинам). Другой вариант - учесть через веса, для этого нужно оценить плотность сэмплирования (именно самого сэмплирования, а не находок - мы могли обследовать два участка, один 2 га, второй 10 га, и найти на обоих по 2 редких вида), в R для этого есть weights (декластеризация - об этом), веса обратно пропорциональны плотности сэмплирования. Но детали зависят от того, какую модель будем строить, в некоторых случаях можно просто использовать данные, например в INLA
А вот вариограмма зависимой переменной, точнее остатков от модели, это о другом.
Учесть ее можно, например оценив sampling efforts (которые могут выражены в обследованной площади или времени, потраченном на обследование), в R для этого есть offset (т.е. переходим к относительным величинам). Другой вариант - учесть через веса, для этого нужно оценить плотность сэмплирования (именно самого сэмплирования, а не находок - мы могли обследовать два участка, один 2 га, второй 10 га, и найти на обоих по 2 редких вида), в R для этого есть weights (декластеризация - об этом), веса обратно пропорциональны плотности сэмплирования. Но детали зависят от того, какую модель будем строить, в некоторых случаях можно просто использовать данные, например в INLA
А вот вариограмма зависимой переменной, точнее остатков от модели, это о другом.
-
bolotoved
- Гуру
- Сообщения: 920
- Зарегистрирован: 30 дек 2008, 14:11
- Репутация: 236
- Откуда: Ханты-Мансийск
- Контактная информация:
Re: "Нормализация" точечных данных в пространстве
Срасибо, за интерес к теме 
Еще задача из этой же области, которая, возможно, поможет прийти к какому-то более универсальному алгоритму подготовки данных ("декластеризации").
Задача такова: сбор данных о глубине торфа ведется с помощью георадара, получаются линии отстоящие друг от друга на сотни метров. Сама линия состоит из точек в каждой точке известна глубина торфяной залежи, но эти точки находятся уже на расстоянии десятков сантиметров друг от друга. Т.о. мы снова имеем существенную неоднородность в семплировании связанную не с какой-то природной особенностью, а с методикой. Тоже надо как-то эти точки разредить перед интерполяцией и тоже встает проблема выбора шага разрежения. Изначально у меня тоже был большой соблазн посмотреть аутокорреляцию между близостью точек и глубиной, но сейчас засомневался.
Максим, я вначале тоже полез в статьи по аутокорреляции, ознакомился с совершенно порясной статьей Лежандра "Пространственная аутокорреляция: проблема или новая парадигма?". Но постепенно начал приходить к пониманию (хотя, полной уверенности так и не достиг), что еще до расчета пространственной аутокорреляции зависимых переменных, нужно что-то сделать с неоднородностью в семплировании.Максим Дубинин писал(а):А по мне так совсем про неё.bolotoved писал(а):P.S. Про пространственную аутокорреляцию я в курсе, это не совсем про нее, похоже.
Да, именно так. Еще добавлю, что в данном случае мы имеем дело с т.н. "неэкспериментальными данными", когда данные получены не в ходе конкретного эксперимента с конкретным дизайном отбора проб, а с данными отбиравшимися по разным принципам, разными людьми, в ходе разных проектов. Нам нужно это как-то унифицировать и декластеризация кажется мне выходом. Хотя м.б. действительно нужно задействовать методы не требовательные к независимости "независимых" переменных.gamm писал(а):строго говоря, речь идет о нарушении независимости "независимых" переменных
Еще задача из этой же области, которая, возможно, поможет прийти к какому-то более универсальному алгоритму подготовки данных ("декластеризации").
Задача такова: сбор данных о глубине торфа ведется с помощью георадара, получаются линии отстоящие друг от друга на сотни метров. Сама линия состоит из точек в каждой точке известна глубина торфяной залежи, но эти точки находятся уже на расстоянии десятков сантиметров друг от друга. Т.о. мы снова имеем существенную неоднородность в семплировании связанную не с какой-то природной особенностью, а с методикой. Тоже надо как-то эти точки разредить перед интерполяцией и тоже встает проблема выбора шага разрежения. Изначально у меня тоже был большой соблазн посмотреть аутокорреляцию между близостью точек и глубиной, но сейчас засомневался.
-
gamm
- Гуру
- Сообщения: 4168
- Зарегистрирован: 15 окт 2010, 08:33
- Репутация: 1107
- Ваше звание: программист
- Откуда: Казань
Re: "Нормализация" точечных данных в пространстве
прореживать ничего не нужно, как и интерполировать (в данной ситуации). Вам лучше привязать ваши данные к каким-то факторам, которые вам известны на всей территории, например рельеф или еще что-то (не представляю процесса торфообразования, и понятия не имею, какая там может быть пространственная вариабельность значений). Опять же, если считать процесс изотропным, то из профилей вытаскивается "пространственный закон" (ковариация-вариограмма), и можно строить случайное поле в INLA. Если данные пришлете, можно попробовать, если время не горит. Если не хотите данные светить, можно в личку.bolotoved писал(а):Задача такова: сбор данных о глубине торфа ведется с помощью георадара, получаются линии отстоящие друг от друга на сотни метров. Сама линия состоит из точек в каждой точке известна глубина торфяной залежи, но эти точки находятся уже на расстоянии десятков сантиметров друг от друга.
...
Тоже надо как-то эти точки разредить перед интерполяцией и тоже встает проблема выбора шага разрежения.
Но если хочется интерполировать, то данные лучше усреднить по сегментам, размер которых соизмерим с расстоянием между профилями.
-
bolotoved
- Гуру
- Сообщения: 920
- Зарегистрирован: 30 дек 2008, 14:11
- Репутация: 236
- Откуда: Ханты-Мансийск
- Контактная информация:
Re: "Нормализация" точечных данных в пространстве
Данные собраны коллективом из нескольких организаций, я посоветуюсь, постараюсь уговорить выложить.gamm писал(а):bolotoved писал(а):Если данные пришлете, можно попробовать, если время не горит.
-
gamm
- Гуру
- Сообщения: 4168
- Зарегистрирован: 15 окт 2010, 08:33
- Репутация: 1107
- Ваше звание: программист
- Откуда: Казань
Re: "Нормализация" точечных данных в пространстве
Можно даже сделать фиктивный набор данных (чтобы научиться читать), сделать програмульку (на R+INLA), и гоняйте сами. У меня интерес чисто академический.bolotoved писал(а):Данные собраны коллективом из нескольких организаций, я посоветуюсь, постараюсь уговорить выложить.
P.S. в подобных ситуациях обезразмеривают координаты (повернув произвольно систему координат, поместив начало в произвольное место, и поделив на случайное число), а также обезразмеривают данные, приведя их к диапазону 0-1. Для моделирования все это просто не нужно.
Кто сейчас на конференции
Сейчас этот форум просматривают: нет зарегистрированных пользователей и 2 гостя